
Die generative künstliche Intelligenz übt in immer mehr Bereichen großen Einfluss auf mögliche und gewünschte Veränderungen und Verbesserungen aus. Dazu zählt auch der Flugverkehr, wie am folgenden Beispiel der American Airlines zu sehen ist.
Klar, auch Flugbetriebe und der gesamte Flugverkehr können von den Möglichkeiten der generativen künstlichen Intelligenz profitieren. Ob das personalisierte Angebote für Passagiere sind oder vorausschauende Wartungen von Flugzeugen und anderem Equipment – die generative KI bietet hierfür zahlreiche Optionen.
Um diese auch wirklich nutzen zu können, ist das passende Equipment wie ein leistungsstarker Server erforderlich. Allerdings sind Rechner mit herkömmlichen Prozessoren oftmals mit dem Trainieren und Inferenzieren von KI-Anwendungen und -Daten überfordert. An dieser Stelle kommen Software-Lösungen ins Spiel, die dabei helfen sollen, das Beste aus Rechnersystemen in Sachen generative KI herauszuholen.
KI-Anwendungen erfordern leistungsfähige Hardware
Denn eines ist klar: Anwendungen, die auf der generativen KI basieren, sind datenhungrig und erfordern leistungsstarke Rechner. Hierfür werden oft Systeme eingesetzt, in denen sich GPUs (Graphics Processing Unit) vor allem um das Trainieren der riesigen Datenmengen kümmern. Allerdings sind diese KI-Beschleuniger kosten- und energieintensiv.
Daher sind sie für groß angelegte KI-Projekte, wie das oft bei Fluggesellschaften der Fall ist, oft nur zweite Wahl. Denn gerade in Unternehmen wie beispielsweise der American Airlines steht bereits eine IT-Infrastruktur zur Verfügung, die hauptsächlich auf herkömmlichen Prozessoren und weniger auf GPUs fußt.
Der Numenta NuPIC Inferenz-Server macht GPUs überflüssig
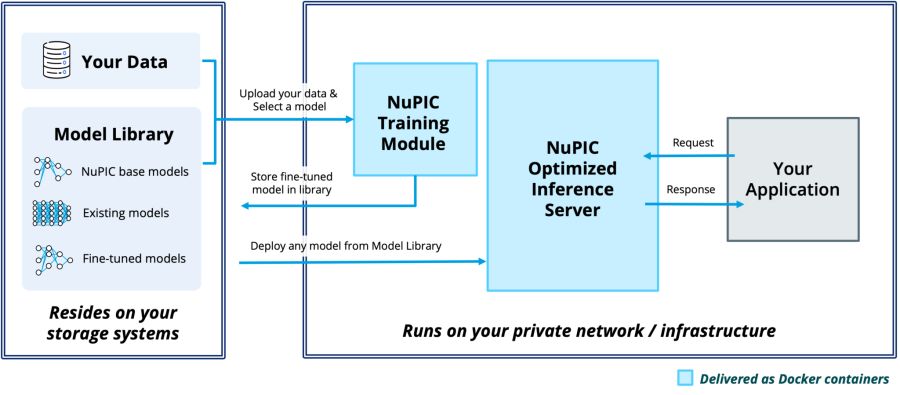
In solch einem Fall ist es vor allem wichtig, die vorhandenen Server-Ressourcen bestmöglich zu nutzen, auch ganz ohne die erforderliche Spezialhardware wie GPUs. Eine hierfür passende Lösung kommt vom auf KI-Lösungen spezialisierten Unternehmen Numenta. Hierbei steht mit der Numenta Platform for Intelligent Computing (NuPIC) ein dedizierter Inferenz-Server zur Verfügung, der vor allem eines sehr gut kann: KI-Befehle mithilfe von Intel AMX-optimiertem Programmcode so schnell wie möglich auszuführen. Damit kann auf den Einsatz von teuren und energiehungrigen GPUs komplett verzichtet werden.
Genau diese Besonderheit macht sich American Airlines schon eine ganze Weile zunutze. Daraus resultierten bis dato zahlreiche Vorzüge. Dazu gehören unter anderem eine deutlich bessere Inferenz-Leistung, eine erhebliche Reduktion von Speicherbedarf und Stromverbrauch sowie ein verbesserter Zugang zu erforderlichen Technologien, was den Einsatz von generativer KI betrifft.
Das Inferenzieren findet im eigenen Rechenzentrum statt
Das Besondere an der Numenta-Lösung ist deren Fähigkeit, sämtliche Inferenz-Jobs lokal, also im Rechenzentrum des jeweiligen Kunden, auszuführen. Hierfür kommen in einem ersten Schritt die eigenen Daten zum Einsatz, die mithilfe von Numenta so lange optimiert werden, bis das gewünschte Ergebnis vorliegt. Anschließend wird die KI-Anwendung mithilfe des Inferenz-Servers so lange trainiert, bis sie genau das liefert, was sie liefern soll.
Hierfür verwendet der NuPIC Inferenz-Server Standard-Protokolle, mit denen er über http-basierte Schnittstellen auf die Datenmodelle zugreift. Im Hintergrund werkelt ein herkömmlicher Triton-Rechner. Damit lässt sich der NuPIC-Server in nahezu jede Standard-MLOps-Lösung wie z. B. Kubernetes integrieren.
Da der Inferenzserver ausschließlich mit Standard-CPUs ausgestattet ist, kann eine einzige Instanz des Servers Dutzende von verschiedenen Modellen parallel ausführen. Dabei läuft jedes Modell in einem separaten Prozess und ist vollständig asynchron. Damit ist keine Stapelverarbeitung oder Synchronisation erforderlich, um einen maximalen Durchsatz zu erreichen. So können generative und nicht-generative Modelle innerhalb derselben Instanz beliebig gemischt und angepasst werden.
Der NuPIC Inferenzserver ist auf Hochleistungsberechnungen ausgelegt
Das Besondere am NuPIC Inferenzserver ist dessen Echtzeit-Engine, die auf sogenannten Cajal-Bibliotheken basiert. Diese sind nach dem Neurowissenschaftler Santiago Ramón y Cajal benannt. Diese Bibliotheken wurden sowohl in C++ als auch in Assembler geschrieben. Damit bieten sie eine optimierte Laufzeit, benutzerdefinierte ONNX-Routinen und eine Reihe von Hardware-Optimierungen, die Intel-eigene SIMD-Anweisungen wie Intel AVX2, Intel AVX512 und Intel AMX nutzen. Das erklärt unter anderem die enorme Leistungsfähigkeit des NuPIC Inferenzservers auf Intel-Hardware.
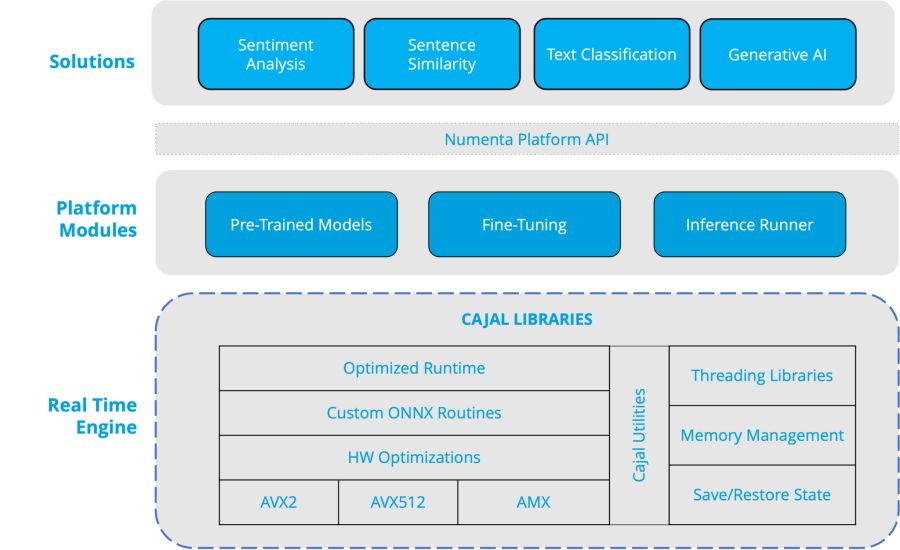
Hierzu trägt vor allem das besondere Design von Cajal bei. Denn diese Engine ist für ein effizientes Minimieren sämtlicher Datenbewegungen ausgelegt, was die erforderliche Speicherbandbreite erheblich beschränkt. Gleichzeitig sollen spezielle Routinen die Verwaltung der vorhandenen L1- und L2-Caches maximieren.
Damit lässt sich die langfristige Strategie von American Airlines mithilfe von Intel und Numenta offenkundig schneller erreichen als ursprünglich angenommen. Denn das Realisieren von KI-Projekten auf Basis der generativen KI auf verfügbarer Hardware ist eines der wesentlichen Aspekte bei der digitalen Transformation des Unternehmens.
Disclaimer: Für das Verfassen und Veröffentlichen dieses Blogbeitrags hat mich die Firma Intel beauftragt. Bei der Ausgestaltung der Inhalte hatte ich nahezu freie Hand.